
Introduction
According to the WHO (2021), more than a billion people worldwide experience some form of disability including almost 240 million children whose well-being is endangered. As also highlighted in a report of UNICEF (2021), the ageing of the world population, new illnesses and an escalating trend of chronic diseases further increase the amount of disabled people. They just need a little help to live and work independently and with dignity.
Aiming to assist loved ones, and often themselves, people started designing low-tech devices many centuries ago (Robitaille, 2010). Since the early sixteenth century, people with mobility difficulties have been using the walking cane as a tool that assists them to walk and stand stably (Amato, 2004). Although wheeled seats and furniture have been used for transporting disabled people since sixth century BCE, mass production of wheelchairs started in 1933, when the paraplegic Everest and his friend Jennings designed a metal foldable wheelchair that used the X-brace design they patented as a “construction for collapsible invalids’ wheelchairs” (Woods and Watson, 2004).
Glasses for partially sighted people were invented in the seventeenth century (Rosenthal, 1996; Lee, 2013). At the same time, ear trumpets, passive amplifiers that collect sound waves, and direct them into the ear channel, replaced the cupped hand, the popular method for hard of hearing used since Roman Emperor Hadrian’s era (Valentinuzzi, 2020). These two sensory tools are the origins of modern assistive devices and technologies that support a more independent life for people with disabilities (Robitaille, 2010).
Blind people were unable to independently learn and study until the beginning of the nineteenth century. At that time, Louis Braille, who was blind since his early childhood, modified the military purpose language created by Charles Barbier de la Serre and invented the Braille alphabet, which is still among the most widely used reading media for the blind (Jiménez et al., 2009). In 1935, Agatha Christie’s novel The Murder of Roger Ackroyd was recorded, initiating the transition of the printed toward the so called talking books (Philips, 2007). Electronic text-to-speech synthesizers were unveiled just a few years later, enabling blind people to consume written content by leveraging their enhanced hearing ability (Ohna, 2010).
The first electronic assistive technology ever developed was the Akouphone, a portable hearing device with carbon microphone and earphones (Kenefick, 2009). Although communication based on hand movements is mentioned in Plato’s Cratylus, a Socratic’ dialogue from his middle period as early as the fifth century BCE (Cratylus, 2022), the first sign language in wide use was the Old French Sign language, which originated in the eighteenth century and became the basis of American Sign language (Reagan, 2021).
All these developments and tools significantly improved the condition of people with disabilities in their daily communications, although their comprehensive education was still challenging. To ensure the fundamental human right to education and avoid the discrimination due to disability, in 2018 WHO launched the global cooperation on assistive technology (GATE) initiative (Boot et al., 2017). The only goal of GATE is “to improve access to high-quality affordable assistive products globally” (WHO, 2018).
Artificial Intelligence (AI) is the driving force of most assistive products, supporting people with different disabilities to keep and improve their education and everyday activities (Zdravkova, 2022). It enabled the creation of simulated environments that also include augmented and virtual reality. AI-supported tools improve visual tracking skills, help students with social disabilities and improve time-management skills.
The advantage of AI technologies over non-AI technologies used to date is the speed and precision they provide in analyzing and deciphering complex communication, expression, and visual behaviors. For example, applications that incorporate gesture-based text prediction in conjunction with AI are very useful for categorizing the most likely words from gestures and transforming them into meaningful sentences that support people with hearing impairments (Cheng and Lai, 2020). Other examples include machine and deep learning, which can improve substantially EEG-based brain-computer interfaces that help people who are unable to move gain independence (Sakti et al., 2021).
In this study, we present the findings of a narrative literature review that collected relevant literature published during the last ten years (Baumeister, 1997). The first step in this method pertains to conducting a preliminary search of the literature. For this reason, we constructed a search string to query the Scopus research database. In this endeavor, we have included papers only written in English that highlight evidence related to the impact of AI on modern assistive technologies for children with disabilities. As a next step, we analyzed and refined the explored topics from the relevant papers by subsequently identifying the employed AI technique to support and enhance the functionality of the assistive technologies. After a careful review, we classified the AI techniques into four different clusters, namely, augmentative and alternative communication (AAC), machine and deep learning (ML and DL), natural language processing (NLP), and Conversational AI.
The remainder of the paper is organized as follows: in the next section, a variety of disabilities will be explored and the cutting-edge assistive technologies that support communication and education of young children will be announced in line with AI technologies that enabled their creation. This section will be followed with a brief explanation of AI algorithms and techniques behind the announced assistive technologies including the futuristic ones. The paper will conclude with an AI perspective of future assistive technologies and ethical concerns that arise from the use of cutting-edge communication and learning assistive technologies intended for disabled children.
Cutting edge assistive technologies
Unhindered communication is the key prerequisite of quality education (Dhawan, 2020). If a student cannot listen to what a teacher presents and school mates talk about, or cannot see the visual content that supports the lectures and the assignments, then the effect of instructional behavior exhibited even by the most skilled teachers is reduced. Lack of attention, cognitive and intellectual preparedness to comprehend the school curriculum is an additional problem. Sometimes, perfect sight, hearing and intellectual abilities are obstructed by motor disabilities, which slow down or disable students’ ability to write. Cutting-edge assistive technologies can mitigate many of the above-mentioned problems (Shinohara and Wobbrock, 2011).
According to American Speech-Language-Hearing Association (ASHA), communication disorders cover the impairments “in the ability to receive, send, process, and comprehend concepts or verbal, non-verbal and graphic symbol systems” (American Speech-Language-Hearing Association, 1993). They are classified into speech disorders, language disorders, hearing disorders, and central auditory processing disorders (American Speech-Language-Hearing Association, 1993).
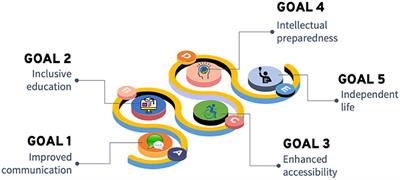
The modern assistive technologies empowered by AI can significantly contribute to achieving important goals to support and provide new possibilities for children with disabilities. In Figure 1 we illustrate such goals, which include improved communication, inclusive education, enhanced accessibility, intellectual preparedness, and culminating with independent life.
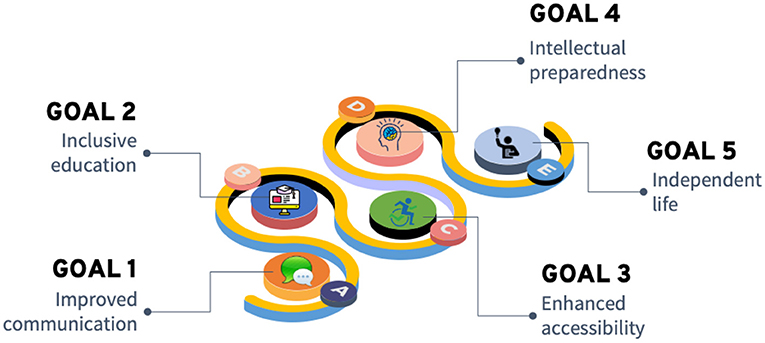
Figure 1. AI enabled goals to support children with disabilities.
As mentioned earlier, the AI techniques were classified into four broad clusters: AI methods and algorithms that support AAC; ML and DL; NLP; and Conversational AI – speech and voice recognition, which are further divided into silent speech interface (SSI), speech recognition (SR), visual speech recognition, and voice recognition. These four clusters should not be mixed with the AI goals that according to Russel and Norvig (http://aima.cs.berkeley.edu/) embrace: problem solving; reasoning; knowledge representation; planning; machine learning; communication, perceiving and acting. Deep learning and natural language processing are important AI subsections and tools, while conversational AI is an umbrella term of so called affective computing, which is an interdisciplinary field that relies on AI. AAC is not AI per se. Similarly to affective computing, it heavily relies on sophisticated AI. Although AI heterogeneous, the division was made according to the needs of assistive technologies, thus they are a symbiosis of AI methods and major trends in assistive technologies.
Table 1 lists on the first column the senses or the human ability being affected. For each sense then a disorder is listed (column two) followed by the appropriate assistive technologies (column three) designed to easier overcome the challenges associated with the disorder. In the table’s last two columns, we list AI techniques and AI algorithms and methods respective of the listed assistive technologies. The main criteria when selecting the listed disorders was their impact on impaired communication and the availability of Scopus studies describing the appropriate assistive technologies. If multiple studies introduced the same assistive application, priority was given to the one that in more detail represents an implementation of the AI technologies, algorithms, and methods.
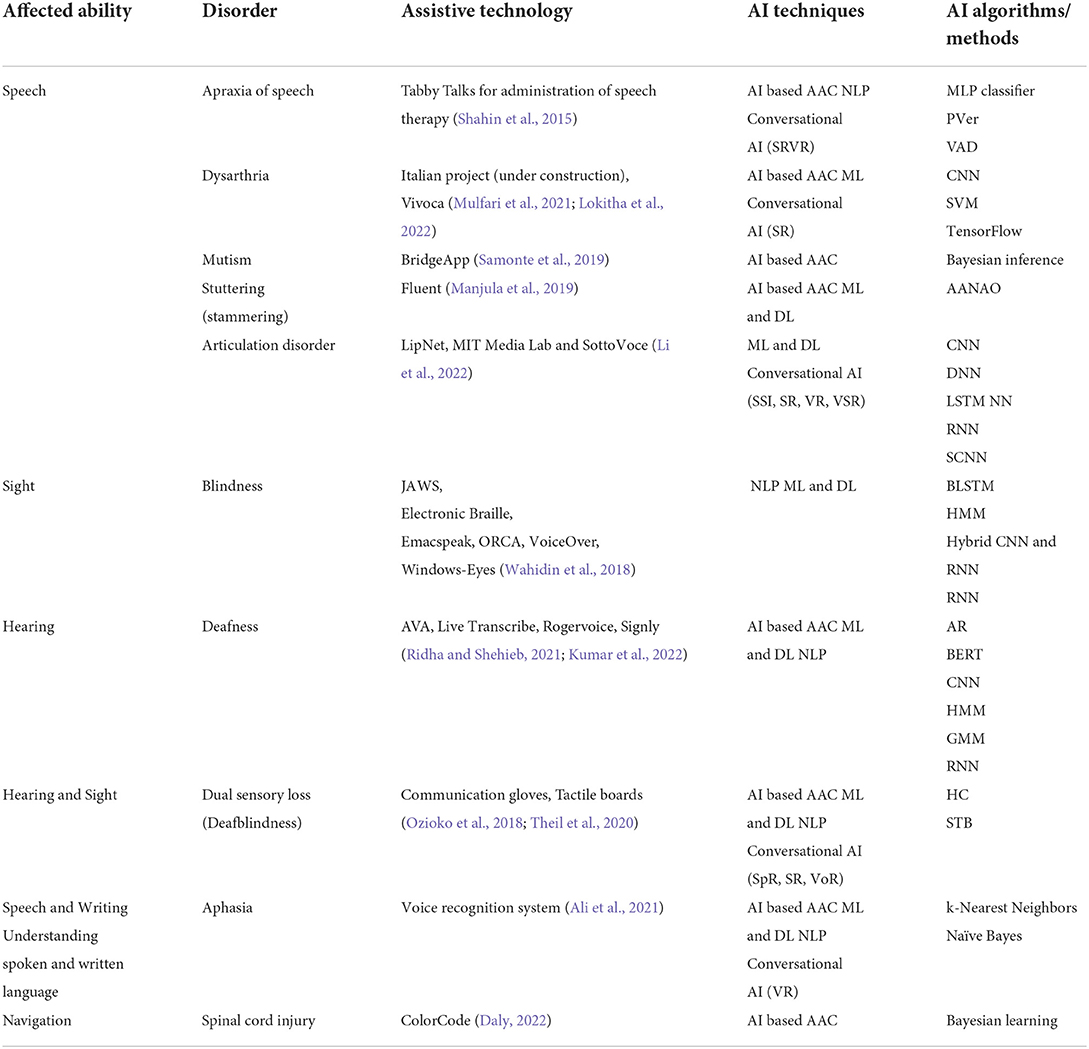
Table 1. Assistive technologies aligned to impaired communication disorders.
The following AI algorithms and methods were used to develop the assistive technologies shown in the table: adaptive optimization based on artificial neural networks (AOANN), augmented reality (AR), Bayesian learning, Bidirectional Encoder Representations from Transformers (BERT), Bidirectional long short-term memory (BLSTM), Convolutional neural networks (CNN), Deep neural networks (DNN), Gausian Markov model, Haptic communication (HC), Hidden Markov model (HMM), Hybrid CNN and RNN, k-Nearest Neighbors, Multi-layer perceptron (MLP) classifier, Naïve Bayes, Pronunciation verification, Recurrent neural network (RNN), Spatiotemporal convolutional neural network (SCNN), Speaker recognition (SpR), Speech-to-Braille, Speech-to-text (STT), Support vector machines (SVM), TensorFlow, Text-to-speech (TTS) and Voice activity detection (VAD).
AI algorithms presented in the table were selected in three stages:
a) Determination of the most frequent communication disorders covered by American Speech-Language-Hearing Association (ASHA, https://www.asha.org), mental disorders from World Health Organization (https://www.who.int), as well as learning difficulties listed in the UNESCO learning portal (https://learningportal.iiep.unesco.org/);
b) Selection of the relevant scholar articles that present AI-based assistive technologies created to support this communication and learning disorders;
c) Thorough examination and extraction of AI methods, algorithms and techniques and their clustering.
Next subsection introduces them briefly by presenting a short explanation of each of the implemented AI algorithms and the assistive technologies that were developed by implementing those algorithms. Then, AI-based assistive technologies from all four clusters are also introduced and illustrated.
AI algorithms and assistive technologies for communication and learning impaired students
The list of the algorithms in the previous section was alphabetically ordered. The introduction of AI algorithms within the subsection will start with artificial neural networks, which are the most widely used computational model in machine learning and the heart of deep learning. The list will continue with the learning algorithms, then it will introduce speech and text conversions and end with haptic technology.
Since the mid 1980s, artificial neural networks have become a very powerful model that enables excellent prediction and learning of many patterns that cannot be explicitly presented. According to Pai (2020), three types of neural networks contribute to deep learning: artificial neural networks (ANN), CNN, and RNN. ANNs are feedforward networks capable of learning nonlinear functions. Their limitations can be overcome by creating building blocks (CNN) or by adding a recurrent connection on the hidden state (RNN). CNNs are particularly valuable for image processing, while RNNs solve problems with time series, text and audio data (Pai, 2020). Combination of CNNs and RNNs, sometimes called hybrid CNN and RNN proved its efficiency for word prediction (Goulart et al., 2018). Spatiotemporal convolutional neural networks are a special type of CNNs capable of extracting spatial-temporal features. They are very efficient for sign language recognition (Li et al., 2022). More complex neural networks with many hidden layers that employ more sophisticated mathematical models belong to deep neural networks.
Bidirectional Encoder Representations from Transformers (BERT) is a language representation model that is trained on unlabeled data over different pre-training tasks using multi-layer bidirectional transformer encoders (Devlin et al., 2018). BERT is embedded into Google Search for over 70 languages. It has been successfully used in several assistive technologies, particularly for speech recognition (Brunner et al., 2020) and speech completion (Tsunematsu et al., 2020). Model performance of classification problems of sequential data can be improved by BLSTM. It is particularly useful for developing assistive technologies for people with visual impairment (Wahidin et al., 2018).
Artificial neural networks adaptive optimization is an effective classifier that was used to predict the disfluencies in speech signals of people with stuttered speech (Manjula et al., 2019). It adaptively optimizes network architecture using the artificial fish swarm optimization method, which implements stochastic search (Manjula et al., 2019).
k-Nearest Neighbors is non-parametric, supervised learning classifier, which is widely used for computing the distances from the test example to all stored examples. It was abundantly used for classification and regression in the voice recognition systems (Ali et al., 2021).
Support vector machines are supervised learning models used for pattern classification (Cortes and Vapnik, 1995). They were used for developing the smart voice conversational assistant (Lokitha et al., 2022).
The term Bayesian learning has been interchangeably used with Bayesian inference. It produces a probability distribution using the Bayes’ theorem to predict the value of an unknown quantity (Neal, 2012). Naïve Bayes classifiers are a simple class of Bayesian networks capable of efficient classification and prediction. Bayesian learning and naïve Bayes have been successfully used to develop BridgeApp, an assistive mobile application that assists communication between people that are deaf and mute (Samonte et al., 2019).
Hidden Markov model is a statistical Markov model that supports modeling of an observable process using unobservable states. Gausian hidden Markov models expect that the observation probability distribution is Gausian (or normal). These two finite-state models establish correlations between adjacent symbols, domains, or events, which is crucial for speech recognition.
Speaker, speech and text recognition are crucial to enable smooth communication with and among people with more severe hearing and visual impairment. Speaker and speech recognition identify words spoken aloud and convert them into readable text presented with written or Braille alphabet (Benzeghiba et al., 2007). They implement almost all AI algorithms to develop various assistive technologies, such as AVA, Jaws or RogerVoice (Zdravkova and Krasniqi, 2021). Assessment of speech in TabbyTalks (Shahin et al., 2015) implements (VAD, Sohn et al., 1999).
Augmented reality (AR) is an umbrella term that embraces interactive experience by integrating 3D virtual objects into a 3D environment in real time (Azuma, 1997). AR has been widely used in various assistive technologies, including the popular live captioning system AVA (https://www.ava.me/), which enables deaf and hard-of-hearing to read the spoken lectures.
People with dual sensory loss can rely on haptic communication (HC), that enables tactile communication and interaction via the sense of touch (Ozioko et al., 2018). Many assistive technologies use the open source software library TensorFlow library (www.tensorflow.org), which was developed by Google.
AI-based assistive technologies
In all the presented assistive technologies, AI has been abundantly used. Augmentative and alternative communication methods proved their significant role in at least half of them. Assistive technologies related to hearing or visual deficiency are developed using neural natural language processing algorithms, which are a symbiosis between natural language processing and deep learning. The predominance of neural and deep networks is also obvious, proving that new assistive technologies are machine learning powered.
AAC is the best assistive remedy for intelligibility, which is mildly or more severely disrupted by speech disorders, including: aphasia, apraxia of speech, articulation disorder, cluttering, dysarthria and stuttering (Kent, 2000). It can also be affected by cognitive problems, such as autism spectrum disorder (ASD), dyslexia and Down syndrome (Deb et al., 2022; Krasniqi et al., 2022), and by motor disabilities, for example cerebral palsy, multiple sclerosis, and Parkinson’s disease (Stipancic and Tjaden, 2022). Assistive devices and technologies that are used to improve intelligibility are among the most prominent AAC devices and technologies (Norrie et al., 2021). Although the success of high-tech AAC is still limited, mainly due to “infrastructure, policy, and recruitment deficits”, their advancement is inevitable and they will soon “serve as mediator between teacher, aided communicator, and their assistive technology” (Norrie et al., 2021). It is expected that in the near future, AAC devices will be combined with non-invasive methods of access to the brain-computer interface, which will revolutionize communication (Luo et al., 2022). However, without powerful machine learning and neural imaging technology, this transformation will never become true.
Within most of the reviewed devices and technologies, machine learning is developed alongside deep learning. It is particularly powerful in the technologies related to speech and sound production, as well as with spoken and written language understanding (Jobanputra et al., 2019). Neural network brain-computer interfaces (NNBCI) have a potential to reduce disability by translating neural activity into control of assistive devices (Schwemmer et al., 2018).
Speech and voice recognition will never be possible without artificial intelligence (Singh et al., 2018). All modern deep learning techniques, including BERT (Brunner et al., 2020) contribute to better speech, voice and speech recognition (Amberkar et al., 2018). Non-invasive brain-computer interfaces emerge in this area, leading to much better performance compared to traditional systems that process auditory and visual information (Brumberg et al., 2018). United with deep learning methods and architectures, they “boost classification performance” of algorithms for computer vision and natural language processing (Singh et al., 2018).
Most of the tools introduced in this section have been developed to accommodate the needs of students starting from elementary education to the college level. On some occasions, they can be applicable even for elderly people. While the concept of AI technologies presented so far was mainly related to applications in the education sector, AI has also the potential to improve health and well-being of elderly people. Some forms of AI assistive technologies such as autonomous robots, AI-enabled health applications, voice-activated devices and intelligent homes could tackle the key aging related challenges.
Cutting-edge technologies should be carefully designed and should consider privacy and content. While children with disabilities are more familiar with the use of phones, which facilitate the design and implementation of AI technologies, more mature people need assistance for an independent life. To provide AI technologies to elderly people, designers and programmers of these technologies should implement some considerations tailored to their needs: ensure the participation of elderly people for development of AI technologies, cross-age data collection, investments in digital infrastructure, increased research to understand new uses of AI and how to avoid bias (WHO, 2022).
To conclude, cutting-edge technologies significantly improve communication and learning of people with disabilities, and particularly of young children who were born with technology and do not hesitate to use them without any effort and resistance. Next section will try to prove this claim by researching more thoroughly the four clusters announced in the introduction of this section.
AI technologies that support communication and learning assistive technologies
Augmentative and alternative communication
Certain people with disabilities cannot use speech as their primary means of communication and need therefore to find an alternative way or specific techniques to express themselves. The idea of Augmented and Alternative Communication (AAC) is to use all the abilities that a person has, in order to compensate for the impairment of the verbal communication capacity (Chirvasiu and Simion-Blândă, 2018). In other words, the AAC system provides effective communication to maximize quality of life. There exist various types of AAC that can be chosen depending on the individual’s skill and communication needs (Beukelman et al., 2013). The ACC systems are classified as unaided and aided. Unaided systems do not require a physical aid or tool (e.g., facial expressions, sign language). Aided systems, on the other hand use materials or tech devices which are categorized as:
– Low -tech devices (symbol boards, choice cards, communication books)
– High-tech devices (AAC apps on mobile devices, speech-generating devices or communication devices)
The rapid development of AI has recently opened up new ways to address more and more complex challenges, such as for instance, helping people with complex communication needs to overcome barriers (Delipetrev et al., 2022).
AI powerful tools have the capability of transforming AAC systems such as low-tech with words and symbols and high-tech with computers that employ a human voice for output (Beukelman et al., 2013). Below, AI technologies embedded in the AAC are presented with an analysis of how these tools are being developed and deployed to meet the diverse needs of users.
As part of the UNICEF’s Innovation Fund Investments in Skills and Connectivity (OTTAA Project: AI Algorithms for Assistive Communications, 2022) a platform (OTTAA project) is developed, which is considered to be the first augmentative and alternative communication (AAC) platform that uses a combination of powerful AI algorithms (NLP and ML) and pictogram-based communication code to create sentences and communicate effectively. OTTAA platform allows speech-impaired people to communicate and express themselves using a simple three-tap interaction. Using appropriate pictogram-based communication and AI algorithms children with disabilities will have the opportunity to communicate better and faster (OTTAA Project: Accessible Communication for Children with Disabilities, 2022). In order to encourage more diversity and options for users, the algorithm is trained constantly by analyzing more than 1.8 million sentences previously created by other users. OTTAA is an open source platform that encourages people to participate in improving the source code, in this way it creates an environment where everyone feels that they are contributing.
Image recognition technologies are considered pivotal in inclusive education to make learning accessible and effective. GoVisual app is a program converting photos and videos into literacy and communication opportunities on an iPhone or iPad (GoVisual™, 2022). This innovative approach combines computer vision using the image recognition technology (collecting photographs and videos), the NLP tools to help in story creation, and finally the ML to help identify objects and shapes for ease of programming (Tintarev et al., 2016). Combination of these three techniques creates a potential of independence and self-determination for children with disabilities in their school environment.
HearMeOut app is an application which incorporates both gesture-based text prediction and pictogram-based augmentative and alternative communication using AI. The application uses Natural Language Conversation (Srivastava, 2021) enabling the disabled users to engage in conversation using Speech Recognition. It also uses a word level sign language dataset (Li et al., 2022) to categorize the most probable words from the gestures of the impaired person captured using a camera and then transforms them into the most meaningful and possible sentence using state-of-the-art algorithms. Another positive aspect to this approach is the security concerns; the application does not store the user data because of the continuous process of input and output without storage, which minimizes the chances of any data leakage.
“Fluent” is an AI Augmented Writing Tool which assists persons who stutter to identify words that they might struggle pronouncing and presents a set of alternative words which have similar meaning but are easier to pronounce. The overall landscape of AI-based writing tools is typically comprised of NLP based software systems (Ghai and Mueller, 2021) as in this app but in addition it uses AL (active learning, that is the subset of machine learning; Settles, 2011) to identify whether it can help learn the unique phonetic patterns that an individual might struggle pronouncing. The app does not intend to improve the stutter condition but helps camouflage it.
Machine and deep learning
The recent increase in computing capabilities has enabled ML algorithms to further enhance the functionalities of assistive technologies. The incorporation of ML into eye tracking technology can contribute to the development of smarter assistive systems for people with disabilities (Koester and Arthanat, 2018; Yaneva et al., 2020).
In a study conducted by Valliappan et al. (2020), ML is leveraged to demonstrate accurate smartphone-based eye tracking without any additional hardware. The study results highlight the utility of smartphone-based gaze for detecting reading comprehension difficulty and confirms findings from previous studies on oculomotor tasks. Another work was conducted by Deepika and Murugesan (2015) to facilitate the interactions between computers and people with special needs using eye tracking technology. The performance accuracy of the proposed system under good lightning conditions was 97%.
Additional research efforts are concentrated on people with motor disabilities for a hands-free computer interaction (Šumak et al., 2019), to measure the variation between fixations and saccades using K-means analysis (König and Buffalo, 2014), and for training purposes to control eye gaze via VR (Zhang and Hansen, 2019).
Research advances in machine and deep learning have also contributed to improved electroencephalogram (EEG) decoding and target identification accuracy. In this perspective, visual evoked potential (VEP) based brain-computer interface (BCI) systems are widely explored, mainly due to low user training rate (Waytowich et al., 2016). One research involving people with motor and speech disabilities to evaluate a new monitor for generating VEP for daily BCI applications is conducted by Maymandi et al. (2021). The target identification in this study was performed using DNN. Moreover, DNN have become a useful approach to improve classification performance of BCI systems using EEG signals (Kwak et al., 2017; Craik et al., 2019).
A framework for brain electrical activity-based VEP biometrics is proposed by Palaniappan and Mandic (2007). In this work, in order to improve the classification accuracy, authors utilized k-Nearest Neighbors (kNN), Elma Neural Network (ENN) classifiers and 10-fold cross validation classification.
Video accessibility is of paramount importance for blind and visually impaired individuals for education and other purposes. Computer vision applications show promising results on removing the accessibility barriers, especially toward helping blind people to better sense the visual world. The most recent applications of ML in computer vision are object detection and classification and extraction of relevant information from images or videos.
A machine learning based approach to video description by automating video text generation and scene segmentation is proposed by Yuksel et al. (2020). The quality of the video descriptions generated through this system compared to the human-only condition resulted in being rated higher by blind and visually impaired users. A multimodal comprehensive accessibility framework to generate accessible text and tactile graphics for visually impaired people is suggested by Cavazos Quero et al. (2021). The framework uses machine learning, i.e., image classification technique to classify various kinds of graphics and applies simplification methods to the graphics category. Recently, interactive machine learning (IML) is utilized to support interface design through workshops with disabled users (Katan et al., 2015). This work demonstrates IML’s potential significance as a design tool, expediting the design process by allowing the swift mapping of participant observations into prototypes.
Natural language processing techniques
Screen and text magnifiers are very useful solutions for low vision people, enabling them to read and adjust text. They zoom in the whole screen or a selected section of the screen without any AI techniques utilized. On the other hand, screen readers, Braille displays, and speech recognition software assistive technologies for blind people are completely AI based (Choi et al., 2019).
Screen readers are a compulsory part of all the popular learning management systems: Blackboard Learn, Brightspace D2L, Canvas LMS and Moodle (Zdravkova and Krasniqi, 2021). JAWS is embedded in all of them with Chrome, NVDA, TalkBack, ORCA and VoiceOver as alternative text-to-speech plugins (Oh et al., 2021). As a standalone application or part of Web applications, screen readers support image and touchscreen accessibility (Oh et al., 2021). Apart from speech, they enable non-speech audio, vibration, tactile and force feedback (Oh et al., 2021).
Screen readers consist of two components: optical character recognition (OCR) that recognizes text, images and mathematical expressions; and text-to-speech (TTS), which delivers that content in the form of speech (Suzuki et al., 2004). They can be additionally enhanced by a machine translator enabling language localization (Suzuki et al., 2004).
OCR passes through several phases, three of which are AI-powered: image pre-processing that removes the potential distortions and transforms the image into light and dark areas; intelligent character recognition that compares scanned characters with the learned ones; and post-processing that corrects the errors (Chaudhuri et al., 2017). Past OCR algorithms for text recognition were realized with pattern recognition and ML techniques (Rao et al., 2016). Recent algorithms unite the following soft computing constituents: fuzzy sets, artificial neural networks, genetic algorithms, and rough sets (Rao et al., 2016).
Image recognition is enhanced by image captioning tools, which generate textual description of visually presented objects using template-based, retrieval-based and neural networks-based methods (Wang et al., 2020). Template-based method is a statistical modeling method that uses HMM, Maximum Entropy Markov Models, and Conditional Random Fields to recognize and machine learn the patterns (Wang et al., 2020). The retrieval-based method measures the visual similarity between a new image and an already interpreted image and generates a human-level sentence (Wang et al., 2020).
Recognition of mathematical expressions and formulas, including the handwritten ones consists of character recognition and structure recognition (Veres et al., 2019). Both recognition tasks depend on various ML methods, such as Bayesian inference, fuzzy logic, and neural networks (Veres et al., 2019).
At the end of the OCR part, information is stored as data or text waiting to be converted into voice. The conversion is done by TTS systems, which is a pure natural language processing task (Mache et al., 2015). It consists of text analysis, phonetic analysis, prosodic analysis, followed by speech synthesis (Adam, 2020). Deep neural networks are the most frequently used methods of modern TTS systems that successfully predict the acoustic feature parameters for speech synthesis (Adam, 2020).
Screen readers, which deliver content into speech or auditory signals, are not suitable for deafblind people. The best alternative are text to Braille translators, which “interpret letters and figures through a tactile display” (Gote et al., 2020). Refreshable Braille displays are fully supported by Blackboard Learn and partially supported by Brightspace D2L (Hsu, 2020). They use AI techniques and methods only during OCR phase (Gote et al., 2020). In contrast, AI is the key factor in the opposite direction: from Braille to text (Hsu, 2020). The system presented in this paper employs a convolutional neural network model for converting a line of Braille into text; a ratio character segmentation algorithm to enable image segmentation; and optical Braille recognition to convert Braille images into text (Hsu, 2020). AI impact for speech recognition will be in more detail explored in the next subsection.
Non-signers, i.e., people who are not familiar with sign language can communicate with deaf people who speak using the translators of sign language into text or speech (Truong et al., 2016). These translators predominantly use ML algorithms to find the correct sign, like convolutional and recurrent neural networks (Bendarkar et al., 2021) or deep learning (Bantupalli and Xie, 2018). A very promising human-machine interface (HMI) device are communication gloves, which have sensors that interpret the motions of sign languages into natural language combining virtual and augmented reality with AAC (Ozioko and Dahiya, 2022). Ozioko and Dahiya (2022) review many of them, for example, Robotic Alphabet (RALPH), CyberGlove, PneuGlove, 5DT Data Glove and Cyberglove, the last two achieving a recognition accuracy higher than 90%. Apart from purely mechanical interpretation of sign language, several research teams started interpreting facial expressions of people using sign language (Cardoso et al., 2020; Silva et al., 2020). A standard CNN and hybrid CNN+LST were successfully used to translate facial expressions in Brazilian Sign Language Libras (Silva et al., 2020). All these technologies abundantly use almost all the AI algorithms and methods, including NLP essentials, which are their driving force (Cardoso et al., 2020).
Text-to-speech and speech-to-text system preferences and extensions, for example Mercury Reader, Voice Typing and Co-Writer Universal are designed for different operating systems and are compatible with different browsers, including (Dawson et al., 2019). They are frequently used by gifted students who are frustrated due to their dyslexia (Dawson et al., 2019). Mobile applications like ReadandWrite and Speak It! Voice Dream Weaver and libraries, such as Bookshare, Audible are helpful to students with reading and writing disorders like dyslexia (Dawson et al., 2019). They benefit from word prediction too. Word prediction is completely AI powered and it implements various approaches. For example, assistive technology for children with cerebral palsy is based on hidden Markov models (Jordan et al., 2020), a successfully commercialized mobile on-device system that applies deep learning (Yu et al., 2018), whereas context-based word prediction is achieved with naïve Bayes that incorporates latent semantic analyses (Goulart et al., 2018).
Although the effect of AI-based conversational agents on people with disabilities or special needs is rather controversial, they are “widely used to support people services, decision-making and training in various domains” (Federici et al., 2020).
Voice and speech recognition
As in many other scenarios that involve people with disabilities, AI and various machine learning algorithms show promising results in challenges associated with voice and speech recognition, speech identification, and speech-to-text service applications.
One type of speech disability is the childhood apraxia of speech (CAS), which treatment involves direct therapy sessions with a speech language pathologist. Such sessions must happen during longer periods, which put high demand on time allocation of pathologists. Moreover, many children needing such one-on-one sessions live in rural areas and expenses associated with therapy sessions prevent many children from getting the required support early on Theodoros (2008) and Theodoros and Russell (2008).
Technology in general, and AI and ML in particular, help in enabling children with challenges to receive satisfactory treatment in their home, which makes it a time- and cost-effective solution. One such solution is shown in a study by Parnandi et al. (2013), where a child’s progress is assessed through the therapist assigning speech exercises to the child, which then are analyzed using AI algorithms and an assessment is given back to the therapist. In a similar study, further details show how the AI automatically identifies three types of anomalous patterns that are associated with CAS: delays in sound production, incorrect pronunciation of phonemes, and inconsistent lexical stress (Shahin et al., 2015). Especially issues related to measuring the inconsistent lexical stress are addressed using deep neural network-based classification tools (McKechnie et al., 2021). Such a tool is beneficial for both diagnosis and treatment by using the Convolutional Neural Network (CNN) model to identify linguistic units that affect the speech intelligibility (Abderrazek et al., 2020) and voice recognition and production (Lee et al., 2021). The latter study also utilized techniques to acquire bio signals from muscle activity, brain activity, and articulatory activity in order to improve the accuracy.
Deep-learning algorithms are also used with people who stutter, which is a speech disorder that is manifested by an addition of involuntary pauses or repetition of sounds (Sheikh et al., 2021). Using a real-time application, the system records a person’s voice, then it identifies and removes stammers by improving speech flow, and then finally produces a speech that is clean from stuttering. The speech flow is improved by implementing an amplitude threshold produced by the neural network model (Mishra et al., 2021).
One type of technology that helps with voice and speech disorders is the STT service. Such services help in maintaining a satisfactory conversation between people living with such disabilities, by capturing their voice and transcribing it into written text that can be read by another person (Seebun and Nagowah, 2020). A form of such disability is also the Functional Speech Disorder (FSD), which is the inability to correctly learn to pronounce specific sounds, such as “s, z, r, l, and th”. Study by Itagi et al. (2019) shows how Random Forest Classifier performs better than other algorithms, such as, Fuzzy Decision Tree and Logistic Regression, when detecting and correcting in real-time FSD cases. These services benefit from the Natural Language Processing (NLP) applied in the STT, which utilizes Google Speech API to convert spoken words into text (Seebun and Nagowah, 2020).
AI-based assistive technologies and remote education
COVID pandemic was a great challenge for all the students, particularly those who have some communication and learning disabilities. Urgent need to transform traditional in-class education to remote education was an inspiration for many AI researchers to start creating cutting-edge assistive technologies and support massive inclusiveness at all levels of education. AI-based assistive technologies played a significant role in supporting them to learn and study remotely (Zdravkova and Krasniqi, 2021; Zdravkova et al., 2022).
The most widely used operating systems: Windows, MacOS, Android, Linux and Ubuntu provide some or all accessibility features, among which: screen readers, personal assistants, switch controls and voice access and control (Zdravkova et al., 2022).
Learning management systems, such as: Blackboard Ally, Brightspace D2L, Canvas and Moodle have full or partial conformance with WCAG 2.1 (WCAG, 2018). WCAG 2.1, abbreviated from Web Content Accessibility Guidelines version 2.1, is a referenceable ISO technical standard in the form of guidelines and resources that ensures web and mobile accessibility. All LMSs have various embedded screen reader tools, JAWS being common for all, increasing their WCAG 2.1 compliance. Blackboard Ally enables speech recognition via screen reader Read Speaker, while Brightspace D2L uses Dragon Inspection. These two learning management systems provide the opportunity to present learning content with a Braille display (Zdravkova and Krasniqi, 2021).
Video-teleconferencing tools, including the most widely used Zoom, Google Meet, MS Teams, BigBlueButton and Blackboard Collaborate have many features supporting students with motor, vision and hearing impairment. They all incorporate screen reader JAWS, as well as different AI-based plugins (Zdravkova and Krasniqi, 2021).
Massive open online courses (MOOCs), for example Coursera, edX, MIT OpenCourseWare, and OpenLearning offer various accommodations for students with hearing impairments in the form of multilingual subtitles, and transmission of page text toward a Braille display device (Zdravkova and Krasniqi, 2021).
Socially responsible universities in the developed countries have abundantly used most of the assistive features intended for hearing and visually impaired students for decades (Zdravkova and Krasniqi, 2021).
AI perspective of future assistive technologies
Many children with speech, hearing, and cognitive challenges have limited communication and access to speech-activated gadgets. However, rapidly advancing AI research is opening the way for the creation of new tools to aid in the resolution of these communication issues.
AI has already shown that it has the ability to transform special education and improve results for students with impairments in a variety of ways. Children with ASD who have trouble understanding others’ emotions have benefited from AI-driven applications and robots that assist them practice emotion identification and other social skills. Moreover, AI has influenced the creation of algorithms that can aid in the identification of ASD, specific learning difficulties (dyslexia, dysgraphia, and dyscalculia), and attention-deficit/hyperactivity disorder in students (ADHD). For students with disabilities, AI-enhanced therapies have included error analysis to inform instruction and tailored feedback in spelling and maths.
Despite these gains, gaps in AI research for children with impairments, such as AI for students with intellectual and developmental disabilities, remain to be persistent. Because many of these children have numerous disabilities and/or major health concerns, this is an especially vital area of future work. Children with intellectual and developmental disabilities who also have hearing loss or vision impairment, for example, have additional difficulties. Hearing loss and other health difficulties, such as heart issues, are common among Down syndrome students. AI allows for the integration of health data across multiple applications, hence improving the quality of life for these children by promoting independence. This constellation of solutions can aid in the management of student information and the communication of health information among instructors, physicians, and caregivers.
AI algorithms using big data struggle to deal with the individual uniqueness of disabled people (Wald, 2021). There are currently two major issues that prevent the AI use in clinical decision-making in such cases, i.e., a finite amount of labeled data to train the algorithms, and deep neural network models’ black-box nature. We believe these issues may be solved in one of two ways. To begin with, self-supervised representation learning has lately been applied to the development of meaningful dense representation from small chunks of data. Furthermore, reinforcement learning paradigms can learn to optimize in any defined environment using an exploration-exploitation paradigm. Second, explainable artificial intelligence methods can be used to enhance the decision-making transparency and trust by creating meta-information that elucidate why and how a decision was reached, while also recommending the factors that influenced the decision the most. This will allow researchers to concentrate on precision in intervention studies and tailored treatment models, while AI algorithms handle the data collection and analysis process.
Moreover, BCI systems for vision impaired people that use steady state visual evoked potentials to stimulate brain electrical activity that enables communication with or without gaze shifting are already a reality. Electronic retinal implants have already restored sight of few patients with degenerative retinal diseases. Cochlear implants successfully provide a sense of sound to hard of hearing and even to deaf people. New brain implants enable people to formulate words and sentences by using their thoughts supporting simple communication. Few years ago, these achievements seemed to be science fiction. With the current pace of technological development, BCI and brain implants that enhance human senses will soon become a reality enabling better inclusivity of people with disabilities.
Nevertheless, every cutting-edge technology is a double-edged sword. To paraphrase Norberg Winner (Bynum, 2017), new technologies, particularly brain implants “may be used for the benefit of humanity”, but they “may also be used to destroy humanity.”
First challenge of cutting-edge communication devices is undoubtedly their rather high price. For example, JAWS and ZoomText and ZoomText Fusion, which are the most widely used accessibility magnifiers and screen readers, have an annual price ranging from 80 to 160 US$ (Zdravkova, 2022). Assistive tools for hearing impaired students AVA and RogerVoice are slightly cheaper, but still not affordable to many (Zdravkova, 2022). On the other hand, the price of DaVinci Pro HD OCR and Logan ProxTalker exceeds 3000 US$, making them available to few highly privileged students (Zdravkova, 2022). If assistive tools are selectively used, they will amplify economic inequality, i.e., the gap between rich and poor. In some wealthier societies, the gender and racial gap might also increase, sacrificing girls and minority groups.
Second challenge is their impact on patients’ physical and mental health. Still insufficiently tested communication devices might worsen the state of already feeble hearing or vision sensory organs risking to cause incorrigible deafness or blindness (Shanmugam and Marimuthu, 2021). Such problems might be a result of various reliability problems. This challenge raises the question of liability (Zdravkova, 2019). Although promising, deep brain stimulation reflects the “invasive nature of the intervention” (Cagnan et al., 2019). Another problem related to deep brain stimulation is related to anatomical and pathophysiological differences of people who will undergo the intervention, which can result in inconsistent clinical outcomes (Cagnan et al., 2019).
Next challenge is privacy. Many communication devices are wirelessly connected to medical institutions, either as part of research studies or for health monitoring purposes. The increasing trend of cyber-security threats during COVID pandemic disrupted healthcare institutions worldwide (Muthuppalaniappan and Stevenson, 2021). They affected many hospitals, medical research groups, and healthcare workers, but also the World Health Organization and national authorities of many countries (Muthuppalaniappan and Stevenson, 2021). To avoid data leaks, very strict legal privacy frameworks should be created to significantly increase the level of data protection in public health (WHO, 2021).
Final challenge is related to the social acceptability of new technologies (Koelle et al., 2018). According to this research novel technologies and applications “might create new threats, raise new concerns and increase social tension between users and non-users” (Koelle et al., 2018). Many societies are technology skeptical and their first reaction to cutting-edge technologies is full resistance. If officially approved, there will be many disabled people who will be concerned with their impact making a vicious circle, which might worsen the situation instead of improving it.
In order to avoid all the challenges mentioned above, innovation in research should be very responsible. All potential ethical and legal challenges should be anticipated on time, and their remedies should be carefully included into new cutting-edge assistive technologies by design.
Author contributions
KZ, VK, FD, and MF: conceptualization, formal analysis, investigation, and writing–original draft preparation. KZ and FD: methodology, writing–review and editing, and project administration. KZ: supervision. All authors have read and agreed to the published version of the manuscript.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abderrazek, S., Fredouille, C., Ghio, A., Lalain, M., and Meunier, C. (2020). “Towards interpreting deep learning models to understand loss of speech intelligibility in speech disorders – step 1: cnn model-based phone classification,” in Interspeech 2020 (Shanghai), 2522–2526. doi: 10.21437/Interspeech.2020-2239
CrossRef Full Text | Google Scholar
Adam, E. E. B. (2020). Deep learning based NLP techniques in text to speech synthesis for communication recognition. J. Soft Comput. 2, 209–215. doi: 10.36548/jscp.2020.4.002
CrossRef Full Text | Google Scholar
Ali, A. T., Abdullah, H. S., and Fadhil, M. N. (2021). Voice recognition system using machine learning techniques. Mater. Today Proceed. doi: 10.1016/j.matpr.2021.04.075
CrossRef Full Text | Google Scholar
Amato, J. (2004). On Foot: A History of Walking. New York, NY: NYU Press.
Google Scholar
Amberkar, A., Awasarmol, P., Deshmukh, G., and Dave, P. (2018). “Speech recognition using recurrent neural networks,” in 2018 International Conference on Current Trends Towards Converging Technologies (Coimbatore: IEEE), 1–4.
PubMed Abstract | Google Scholar
American Speech-Language-Hearing Association (1993). Definitions of Communication Disorders and Variations. Rockville, MD. doi: 10.1044/policy.RP1993-00208 Available online at: www.asha.org/policy (accessed May 21, 2022).
CrossRef Full Text | Google Scholar
Azuma, R. T. (1997). A survey of augmented reality. Pres. Tel. Virtual Environ. 6, 355–385. doi: 10.1162/pres.1997.6.4.355
CrossRef Full Text | Google Scholar
Bantupalli, K., and Xie, Y. (2018). “American sign language recognition using deep learning and computer vision,” in 2018 IEEE International Conference on Big Data (Seattle, WA: IEEE), 4896–4899.
PubMed Abstract | Google Scholar
Baumeister, R. F. (1997). Writing narrative literature reviews. Rev. Gen. Psychol. 1, 311–320. doi: 10.1037/1089-2680.1.3.311
CrossRef Full Text | Google Scholar
Bendarkar, D., Somase, P., Rebari, P., Paturkar, R., and Khan, A. (2021). Web Based Recognition and Translation of American Sign Language with CNN and RNN. Vienna: International Association of Online Engineering.
Google Scholar
Benzeghiba, M., Mori, D. E., Deroo, R., Dupont, O., Erbes, S., Jouvet, T., et al. (2007). Automatic speech recognition and speech variability: a review. Speech Commun, 49, 763–786. doi: 10.1016/j.specom.2007.02.006
CrossRef Full Text | Google Scholar
Beukelman, D., Mirenda, P., and Beukelman, D. (2013). Augmentative and Alternative Communication. Towson, MD: Paul H. Brookes Pub.
Google Scholar
Boot, F. H., Dinsmore, J., Khasnabis, C., and MacLachlan, M. (2017). Intellectual disability and assistive technology: opening the GATE wider. Front. Pub. Health 5, 10. doi: 10.3389/fpubh.2017.00010
PubMed Abstract | CrossRef Full Text | Google Scholar
Brumberg, J. S., Pitt, K. M., and Burnison, J. D. (2018). A noninvasive brain-computer interface for real-time speech synthesis: the importance of multimodal feedback. IEEE Trans. Neural Syst. Rehab. Eng. 26, 874–881. doi: 10.1109/TNSRE.2018.2808425
PubMed Abstract | CrossRef Full Text | Google Scholar
Brunner, A., Tu, N. D. T., Weimer, L., and Jannidis, F. (2020). “To BERT or not to BERT-comparing contextual embeddings in a deep learning architecture for the automatic recognition of four types of speech, thought and writing representation,” in SwissText/KONVENS (Zurich).
Google Scholar
Bynum, T. W. (2017). Ethical Challenges to Citizens of ‘The Automatic Age’: Norbert Wiener on the Information Society. Computer Ethics. New York, NY: Routledge.
Google Scholar
Cagnan, H., Denison, T., McIntyre, C., and Brown, P. (2019). Emerging technologies for improved deep brain stimulation. Nat Biotechnol. 37, 1024–1033. doi: 10.1038/s41587-019-0244-6
PubMed Abstract | CrossRef Full Text | Google Scholar
Cardoso, M. E. D. A., Freitas, F. D. A., Barbosa, F. V., Lima, C. A. D. M., Peres, S. M., and Hung, P. C. (2020). “Automatic segmentation of grammatical facial expressions in sign language: towards an inclusive communication experience,” in Proceedings of the 53rd Hawaii International Conference on System Sciences (Hawaii).
Google Scholar
Cavazos Quero, L., Bartolomé, J. I., and Cho, J. (2021). Accessible visual artworks for blind and visually impaired people: comparing a multimodal approach with tactile graphics. Electronics 10, 297. doi: 10.3390/electronics10030297
CrossRef Full Text | Google Scholar
Chaudhuri, A., Mandaviya, K., Badelia, P., and Ghosh, S. K. (2017). Optical Character Recognition Systems for Different Languages with Soft Computing. Cham: Springer, 9–41.
Google Scholar
Cheng, S. C., and Lai, C. L. (2020). Facilitating learning for students with special needs: a review of technology-supported special education studies. J. Comput. Educ. 7, 131–153. doi: 10.1007/s40692-019-00150-8
CrossRef Full Text | Google Scholar
Chirvasiu, N., and Simion-Blândă, E. (2018). Alternative and augmentative communication in support of persons with language development retardation. Rev. Roman. Pentru Educ. Multidimension. 10, 28. doi: 10.18662/rrem/43
CrossRef Full Text | Google Scholar
Choi, J., Jung, S., Park, D. G., Choo, J., and Elmqvist, N. (2019). Visualizing for the non-visual: enabling the visually impaired to use visualization. Comput. Graph. Forum 38, 249–260. doi: 10.1111/cgf.13686
CrossRef Full Text | Google Scholar
Craik, A., He, Y., and Contreras-Vidal, J. L. (2019). Deep learning for electroencephalogram (EEG) classification tasks: a review. J. Neural Eng. 16, 031001. doi: 10.1088/1741-2552/ab0ab5
PubMed Abstract | CrossRef Full Text | Google Scholar
Daly, M. (2022). “ColorCode: A bayesian approach to augmentative and alternative communication with two buttons,” in Ninth Workshop on Speech and Language Processing for Assistive Technologies (Dublin), 17–23.
Google Scholar
Dawson, K., Antonenko, P., Lane, H., and Zhu, J. (2019). Assistive technologies to support students with dyslexia. Teach. Excep. Children 51, 226–239. doi: 10.1177/0040059918794027
CrossRef Full Text | Google Scholar
Deb, S. S., Roy, M., Bachmann, C., and Bertelli, M. O. (2022). Specific Learning Disorders, Motor Disorders, and Communication Disorders. Textbook of Psychiatry for Intellectual Disability and Autism Spectrum Disorder. Cham: Springer, 483–511.
Google Scholar
Deepika, S. S., and Murugesan, G. (2015). “A novel approach for Human Computer Interface based on eye movements for disabled people,” in 2015 IEEE International Conference on Electrical, Computer and Communication Technologies (Coimbatore: IEEE), 1–3.
Google Scholar
Devlin, J., Chang, M. W., Lee, K., and Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv [Preprint]. arXiv: 1810.04805. Available online at: https://arxiv.org/abs/1810.04805
Google Scholar
Federici, S., Filippis, D. E., Mele, M. L., Borsci, M. L., Bracalenti, S., Gaudino, M., et al. (2020). Inside pandora’s box: a systematic review of the assessment of the perceived quality of chatbots for people with disabilities or special needs. Disability Rehab. Assis. Technol. 15, 832–837. doi: 10.1080/17483107.2020.1775313
PubMed Abstract | CrossRef Full Text | Google Scholar
Ghai, B., and Mueller, K. (2021). “Fluent: An AI Augmented Writing Tool for People who Stutter,” in 23rd International ACM SIGACCESS Conference On Computers And Accessibility. doi: 10.1145/3441852.3471211
CrossRef Full Text | Google Scholar
Gote, A., Kulkarni, T., Jha, S., and Gupta, S. (2020). “A review of literature on braille tab and the underlying technology,” in 2020 5th International Conference on Devices, Circuits and Systems (Coimbatore: IEEE), 333–335.
Google Scholar
Goulart, H. X., Tosi, M. D. L., Gonalves, D. S., Maia, R. F., and Wachs-Lopes, G. A. (2018). Hybrid model for word prediction using naive bayes and latent information. arXiv [Preprint]. arXiv:1803.00985. Available online at: http://hdl.handle.net/10993/52024 (accessed May 28, 2022).
Google Scholar
Hsu, B. M. (2020). Braille recognition for reducing asymmetric communication between the blind and non-blind. Symmetry 12, 1069. doi: 10.3390/sym12071069
CrossRef Full Text | Google Scholar
Itagi, A., Baby, C. J., Rout, S., Bharath, K. P., Karthik, R., and Rajesh Kumar, M. (2019). Lisp Detection and Correction Based on Feature Extraction and Random Forest Classifier in Microelectronics, Electromagnetics and Telecommunications. Singapore: Springer, 55–64.
Google Scholar
Jiménez, J., Olea, J., Torres, J., Alonso, I., Harder, D., Fischer, K., et al. (2009). Biography of louis braille and invention of the Braille alphabet. Surv. Ophthalmol. 54, 142–149. doi: 10.1016/j.survophthal.2008.10.006
PubMed Abstract | CrossRef Full Text | Google Scholar
Jobanputra, C., Bavishi, J., and Doshi, N. (2019). Human activity recognition: a survey. Proc. Comput. Sci. 155, 698–703. doi: 10.1016/j.procs.2019.08.100
CrossRef Full Text | Google Scholar
Jordan, M., Guilherme, N. N. N., Alceu, B., and Percy, N. (2020). Virtual keyboard with the prediction of words for children with cerebral palsy. Comput. Methods Prog. Biomed. 192, 105402. doi: 10.1016/j.cmpb.2020.105402
PubMed Abstract | CrossRef Full Text | Google Scholar
Katan, S., Grierson, M., and Fiebrink, R. (2015). “Using interactive machine learning to support interface development through workshops with disabled people,” in Proceedings of the 33rd Annual ACM Conference on Human Factors In Computing Systems (Seoul: ACM), 251–254.
Google Scholar
Koelle, M., Boll, S., Olsson, T., Williamson, J., Profita, H., Kane, S., and Mitchell, R. (2018). “(Un acceptable!?! re-thinking the social acceptability of emerging technologies,” in Extended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems (Montreal, QC), 1–8.
Google Scholar
Koester, H. H., and Arthanat, S. (2018). Text entry rate of access interfaces used by people with physical disabilities: a systematic review. Assistive Technol. 30, 151–163. doi: 10.1080/10400435.2017.1291544
PubMed Abstract | CrossRef Full Text | Google Scholar
König, S. D., and Buffalo, E. A. (2014). A nonparametric method for detecting fixations and saccades using cluster analysis: removing the need for arbitrary thresholds. J. Neurosci. Methods 227, 121–131. doi: 10.1016/j.jneumeth.2014.01.032
PubMed Abstract | CrossRef Full Text | Google Scholar
Krasniqi, V., Zdravkova, K., and Dalipi, F. (2022). Impact of assistive technologies to inclusive education and independent life of down syndrome persons: a systematic literature review and research agenda. Sustainability 14, 4630. doi: 10.3390/su14084630
CrossRef Full Text | Google Scholar
Kumar, L. A., Renuka, D. K., Rose, S. L., and Wartana, I. M. (2022). Deep learning based assistive technology on audio visual speech recognition for hearing impaired. Int. J. Cognit. Comput. Eng. 3, 24–30. doi: 10.1016/j.ijcce.2022.01.003
PubMed Abstract | CrossRef Full Text | Google Scholar
Kwak, N. S., Müller, K. R., and Lee, S. W. (2017). A convolutional neural network for steady state visual evoked potential classification under ambulatory environment. PloS ONE 12, e0172578. doi: 10.1371/journal.pone.0172578
PubMed Abstract | CrossRef Full Text | Google Scholar
Lee, W., Seong, J. J., Ozlu, B., Shim, B. S., Marakhimov, A., Lee, S., et al. (2021). Biosignal sensors and deep learning-based speech recognition: a review. Sensors 21, 1399. doi: 10.3390/s21041399
PubMed Abstract | CrossRef Full Text | Google Scholar
Li, D., Opazo, C., Yu, X., and Li, H. (2022). “Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (Snowmass Village, CO: IEEE), 1459–1469.
Google Scholar
Lokitha, T., Iswarya, R., Archana, A., Kumar, A., and Sasikala, S. (2022). “Smart voice assistance for speech disabled and paralyzed people,” in 2022 International Conference on Computer Communication and Informatics (Coimbatore: IEEE), 1–5.
Google Scholar
Luo, S., Rabbani, Q., and Crone, N. E. (2022). Brain-computer interface: applications to speech decoding and synthesis to augment communication. Neurotherapeutics 19, 263–273. doi: 10.1007/s13311-022-01190-2
PubMed Abstract | CrossRef Full Text | Google Scholar
Manjula, G., Shivakumar, M., and Geetha, Y. V. (2019). “Adaptive optimization based neural network for classification of stuttered speech,” in Proceedings of the 3rd International Conference on Cryptography, Security and Privacy (Kuala Lumpur), 93–98.
Google Scholar
Maymandi, H., Perez Benitez, J. L., Gallegos-Funes, F., and Perez Benitez, J. A. (2021). A novel monitor for practical brain-computer interface applications based on visual evoked potential. Brain-Comput. Interfaces 8, 1–13. doi: 10.1080/2326263X.2021.1900032
CrossRef Full Text | Google Scholar
McKechnie, J., Shahin, M., Ahmed, B., McCabe, P., Arciuli, J., and Ballard, K. J. (2021). An automated lexical stress classification tool for assessing dysprosody in childhood apraxia of speech. Brain Sci. 11, 1408. doi: 10.3390/brainsci11111408
PubMed Abstract | CrossRef Full Text | Google Scholar
Mishra, N., Gupta, A., and Vathana, D. (2021). Optimization of stammering in speech recognition applications. Int. J. Speech Technol. 24, 679–685. doi: 10.1007/s10772-021-09828-w
CrossRef Full Text | Google Scholar
Mulfari, D., Meoni, G., Marini, M., and Fanucci, L. (2021). Machine learning assistive application for users with speech disorders. App. Soft Comput. 103, 107147. doi: 10.1016/j.asoc.2021.107147
CrossRef Full Text | Google Scholar
Muthuppalaniappan, M., and Stevenson, K. (2021). Healthcare cyber-attacks and the COVID-19 pandemic: an urgent threat to global health. Int. J. Q. Health Care 33, mzaa117. doi: 10.1093/intqhc/mzaa117
PubMed Abstract | CrossRef Full Text | Google Scholar
Neal, R. M. (2012). Bayesian Learning for Neural Networks, Vol. 118. Berlin: Springer Science and Business Media.
Google Scholar
Norrie, C. S., Waller, A., and Hannah, E. F. (2021). Establishing context: AAC device adoption and support in a special-education setting. ACM Trans. Comput. Hum. Int. (TOCHI) 28, 1–30. doi: 10.1145/3446205
CrossRef Full Text | Google Scholar
Oh, U., Joh, H., and Lee, Y. (2021). Image accessibility for screen reader users: a systematic review and a road map. Electronics 10, 953. doi: 10.3390/electronics10080953
CrossRef Full Text | Google Scholar
Ohna, S. E. (2010). Open your eyes: deaf studies talking. Scand. J. Disability Res. 12, 141–146. doi: 10.1080/15017410902992775
CrossRef Full Text | Google Scholar
Ozioko, O., and Dahiya, R. (2022). Smart tactile gloves for haptic interaction, communication, and rehabilitation. Adv. Intell. Syst. 4, 2100091. doi: 10.1002/aisy.202100091
CrossRef Full Text | Google Scholar
Ozioko, O., Hersh, M., and Dahiya, R. (2018). “Inductance-based flexible pressure sensor for assistive gloves,” in 2018 IEEE SENSORS (New Delhi: IEEE), 1–4.
Google Scholar
Palaniappan, R., and Mandic, D. P. (2007). Biometrics from brain electrical activity: a machine learning approach. IEEE Trans. Pattern Anal. Machine Int. 29, 738–742. doi: 10.1109/TPAMI.2007.1013
PubMed Abstract | CrossRef Full Text | Google Scholar
Parnandi, A., Karappa, V., Son, Y., Shahin, M., McKechnie, J., Ballard, K., et al. (2013). “Architecture of an automated therapy tool for childhood apraxia of speech,” in Proceedings of the 15th International ACM SIGACCESS Conference on Computers and Accessibility. ACM, Bellevue, Washington, DC, 1–8.
Google Scholar
Philips, D. (2007). Talking books: the encounter of literature and technology in the audio book. Convergence 13, 293–306. doi: 10.1177/1354856507079180
CrossRef Full Text | Google Scholar
Rao, N. V., Sastry, A. S. C. S., Chakravarthy, A. S. N., and Kalyanchakravarthi, P. (2016). Optical character recognition technique algorithms. J. Theor. Appl. Infm. Technol. 83.
Google Scholar
Reagan, T. (2021). Historical linguistics and the case for sign language families. Sign Lang. Stud. 21, 427–454. doi: 10.1353/sls.2021.0006
CrossRef Full Text | Google Scholar
Ridha, A. M., and Shehieb, W. (2021). “Assistive technology for hearing-impaired and deaf students utilizing augmented reality,” in 2021 IEEE Canadian Conference on Electrical and Computer Engineering (Montreal, QC: IEEE), 1–5.
Google Scholar
Robitaille, S. (2010). The Illustrated Guide to Assistive Technology and Devices: Tools and Gadgets for Living Independently: Easyread Super Large 18pt Edition. Available online at: ReadHowYouWant.com (accessed April 29, 2022).
Google Scholar
Rosenthal, J. W. (1996). Spectacles and Other Vision Aids: A History and Guide to Collecting. Novato, CA: Norman Publishing.
Google Scholar
Sakti, W., Anam, K., Utomo, S., Marhaenanto, B., and Nahela, S. (2021). “Artificial intelligence IoT based EEG application using deep learning for movement classification,” in 2021 8th International Conference on Electrical Engineering, Computer Science and Informatics (Samarang: IEEE), 192–196.
Google Scholar
Samonte, M. J. C., Gazmin, R. A., Soriano, J. D. S., and Valencia, M. N. O. (2019). “BridgeApp: An assistive mobile communication application for the deaf and mute,” in 2019 International Conference on Information and Communication Technology Convergence (Jeju: IEEE), 1310–1315.
Google Scholar
Schwemmer, M. A., Skomrock, N. D., Sederberg, P. B., Ting, J. E., Sharma, G., Bockbrader, M. A., et al. (2018). Meeting brain–computer interface user performance expectations using a deep neural network decoding framework. Nat. Med. 24, 1669–1676. doi: 10.1038/s41591-018-0171-y
PubMed Abstract | CrossRef Full Text | Google Scholar
Seebun, G. R., and Nagowah, L. (2020). “Let’s talk: An assistive mobile technology for hearing and speech impaired persons,” in 2020 3rd International Conference on Emerging Trends in Electrical, Electronic and Communications Engineering (Balaclava: IEEE), 210–215.
Google Scholar
Shahin, M., Ahmed, B., Parnandi, A., Karappa, V., McKechnie, J., Ballard, K. J., et al. (2015). Tabby talks: an automated tool for the assessment of childhood apraxia of speech. Speech Commun. 70, 49–64. doi: 10.1016/j.specom.2015.04.002
CrossRef Full Text | Google Scholar
Shanmugam, A. K., and Marimuthu, R. (2021). A critical analysis and review of assistive technology: advancements, laws, and impact on improving the rehabilitation of dysarthric patients. Handb. Dec. Supp. Syst. Neurol. Disorders 15, 263–281. doi: 10.1016/B978-0-12-822271-3.00001-3
CrossRef Full Text | Google Scholar
Sheikh, S. A., Sahidullah, M., Hirsch, F., and Ouni, S. (2021). Machine learning for stuttering identification: Review, challenges & future directions. arXiv [Preprint]. arXiv: 2107.04057. doi: 10.48550/arXiv.2107.04057
CrossRef Full Text | Google Scholar
Shinohara, K., and Wobbrock, J. O. (2011). “In the shadow of misperception: assistive technology use and social interactions,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (Vancouver, BC), 705–714.
Google Scholar
Silva, E. P. D., Costa, P. D. P., Kumada, K. M. O., Martino, J. M. D., and Florentino, G. A. (2020). Recognition of Affective and Grammatical Facial Expressions: a Study for Brazilian Sign Language in European Conference on Computer Vision. Cham: Springer, 218–236.
Google Scholar
Singh, A. P., Nath, R., and Kumar, S. (2018). “A survey: Speech recognition approaches and techniques,” in 2018 5th IEEE Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering (Gorakhpur: IEEE), 1–4.
Google Scholar
Sohn, J., Kim, N. S., and Sung, W. (1999). A statistical model-based voice activity detection. IEEE Sign. Process Lett. 6, 1–3. doi: 10.1109/97.736233
CrossRef Full Text | Google Scholar
Srivastava, H. (2021). Using NLP techniques for enhancing augmentative and alternative communication applications. IJSRP. 11, 243–245. doi: 10.29322/IJSRP.11.02.2021.p11027
CrossRef Full Text | Google Scholar
Stipancic, K. L., and Tjaden, K. (2022). Minimally detectable change of speech intelligibility in speakers with multiple sclerosis and Parkinson’s disease. J. Speech Lang. Hearing Res. 65, 1858–1866. doi: 10.1044/2022_JSLHR-21-00648
PubMed Abstract | CrossRef Full Text | Google Scholar
Šumak, B., Špindler, M., Debeljak, M., Heričko, M., and Pušnik, M. (2019). An empirical evaluation of a hands-free computer interaction for users with motor disabilities. J. Biomed. Inf. 96, 103249. doi: 10.1016/j.jbi.2019.103249
PubMed Abstract | CrossRef Full Text | Google Scholar
Suzuki, M., Kanahori, T., Ohtake, N., and Yamaguchi, K. (2004). “An integrated OCR software for mathematical documents and its output with accessibility,” in International Conference on Computers for Handicapped Persons. Berlin, Heidelberg, 648–655.
Google Scholar
Theil, A., Buchweitz, L., Gay, J., Lindell, E., Guo, L., Persson, N. K., et al. (2020). “Tactile board: a multimodal augmentative and alternative communication device for individuals with Deafblindness,” in 19th International Conference on Mobile and Ubiquitous Multimedia, 223–228.
Google Scholar
Theodoros, D., and Russell, T. (2008). Telerehabilitation: Current perspectives. Stud. Health Technol. Inform. 131, 191–209.
Google Scholar
Theodoros, D., and Russell, T. (2008). Telerehabilitation: current perspectives. Stud. Health Technol. Inform. 131, 191–209.
Google Scholar
Tintarev, N., Reiter, E., Black, R., Waller, A., and Reddington, J. (2016). Personal storytelling: using natural language generation for children with complex communication needs, in the wild. Int. J. Hum. Comput. Stu. 93, 1–16. doi: 10.1016/j.ijhcs.2016.04.005
CrossRef Full Text | Google Scholar
Truong, V. N., Yang, C. K., and Tran, Q. V. (2016). “A translator for American sign language to text and speech,” in 2016 IEEE 5th Global Conference on Consumer Electronics. IEEE, 1–2.
Google Scholar
Tsunematsu, K., Effendi, J., Sakti, S., and Nakamura, S. (2020). “Neural speech completion,” in INTERSPEECH 2020, 21st Annual Conference of the International Speech Communication Association (Shanghai: Interspeech), 2742–2746. doi: 10.21437/Interspeech.2020-2110
CrossRef Full Text | Google Scholar
Valliappan, N., Dai, N., Steinberg, E., He, J., Rogers, K., Ramachandran, V., and Navalpakkam, V. (2020). Accelerating eye movement research via accurate and affordable smartphone eye tracking. Nat. Commun. 11, 1–12. doi: 10.1038/s41467-020-18360-5
PubMed Abstract | CrossRef Full Text | Google Scholar
Veres, O., Rishnyak, I., and Rishniak, H. (2019). “Application of methods of machine learning for the recognition of mathematical expressions,” in COLINS 2019, 378–389.
PubMed Abstract | Google Scholar
Wahidin, H., Waycott, J., and Baker, S. (2018). “The challenges in adopting assistive technologies in the workplace for people with visual impairment,” in Proceedings of the 30th Australian Conference on Computer-Human Interaction, 432–442.
Google Scholar
Wang, J., Wang, W., Wang, L., Wang, Z., Feng, D. D., Tan, T., et al. (2020). Learning visual relationship and context-aware attention for image captioning. Pattern Recog. 98, 107075. doi: 10.1016/j.patcog.2019.107075
CrossRef Full Text | Google Scholar
Waytowich, N. R., Yamani, Y., and Krusienski, D. J. (2016). Optimization of checkerboard spatial frequencies for steady-state visual evoked potential brain–computer interfaces. IEEE Trans. Neural Syst. Rehab. Eng. 25, 557–565. doi: 10.1109/TNSRE.2016.2601013
PubMed Abstract | CrossRef Full Text | Google Scholar
Yaneva, V., Eraslan, S., Yesilada, Y., and Mitkov, R. (2020). Detecting high-functioning autism in adults using eye tracking and machine learning. IEEE Trans. Neural Syst. Rehab. Eng. 28, 1254–1261. doi: 10.1109/TNSRE.2020.2991675
PubMed Abstract | CrossRef Full Text | Google Scholar
Yu, S., Kulkarni, N., Lee, H., and Kim, J. (2018). “On-device neural language model based word prediction,” in Proceedings of the 27th International Conference on Computational Linguistics: System Demonstrations, 128–131.
Google Scholar
Yuksel, B. F., Kim, S. J., Jin, S. J., Lee, J. J., Fazli, P., Mathur, U., and Miele, J. A. (2020). “Increasing video accessibility for visually impaired users with human-in-the-loop machine learning,” in Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems (Honolulu, HI), 1–9.
Google Scholar
Zdravkova, K. (2019). Reconsidering human dignity in the new era. New Ideas Psychol. 54, 112–117. doi: 10.1016/j.newideapsych.2018.12.004
CrossRef Full Text | Google Scholar
Zdravkova, K. (2022). The potential of Artificial Intelligence for Assistive Technology in Education, Handbook on Intelligent Techniques in the Educational Process, Vol 1. Cham: Springer.
Google Scholar
Zdravkova, K., Dalipi, F., and Krasniqi, V. (2022). Remote education trajectories for learners with special needs during COVID-19 outbreak: An accessibility analysis of the learning platforms. Int. J. Emerg. Technol. Learn. 17. doi: 10.3991/ijet.v17i21.32401
CrossRef Full Text | Google Scholar
Zdravkova, K., and Krasniqi, V. (2021). “Inclusive Higher Education during the COVID-19 Pandemic,” in 2021 44th International Convention on Information, Communication and Electronic Technology (MIPRO). IEEE, 833–836.
Google Scholar
Zhang, G., and Hansen, J. P. (2019). “Accessible control of telepresence robots based on eye tracking,” in Proceedings of the 11th ACM Symposium on Eye Tracking Research and Applications (Denver, CO: ACM), 1–3.
Google Scholar